
There’s a quiet shift happening at the intersection of robotics, computer vision, and automotive engineering — and it’s accelerating faster than most people realize. At this year’s Conference on Computer Vision and Pattern Recognition (CVPR), a brand-new event made its debut: First Workshop on Embodied AI Foundation Model Deployment. Name is a mouthful, sure, but conversations that took place there could genuinely reshape how self-driving vehicles operate over the next decade.
Workshop pulled in some of the most consequential names in the field. Dragomir Anguelov and Alex Kendall were among the speakers. From the automotive world, Tesla AI chief Ashok Elluswamy and XPeng’s AI head Liu Xianming both took the stage. That combination — academia, robotics, and production-scale automotive AI under one roof — made the event unusually substantive. This wasn’t a panel of theorists. These are people shipping systems that real drivers rely on, right now.
What emerged wasn’t a single breakthrough moment. It was something arguably more valuable: a rare, industry-wide alignment around a framework that’s been quietly developing for years.
The central debate — if you can even call it that — was the relationship between two distinct but increasingly intertwined approaches to machine learning for autonomous systems.
First is the Vision-Language-Action (VLA) model. These systems learn directly from human behavior. They take in visual input and natural-language instructions, then produce actions or control commands. What makes them compelling is what’s embedded in every human action they observe: perception, physical intuition, social awareness, risk assessment, and intent. Supervision signal is sparse but extraordinarily rich in meaning. Every time a human driver nudges the wheel or eases off the accelerator, they’re expressing a complex chain of judgment — and VLA models are built to absorb that.
Second is the World Model. Rather than predicting what a person would do, these systems predict what happens next — future states, future observations, future representations of the environment. Every frame of video, every movement, every interaction becomes a training signal. They’re not learning how people behave. They’re learning how reality behaves.
Here’s the part that matters most: researchers at the workshop, including Anguelov and Kendall, agreed that these aren’t competing approaches. They’re complementary. VLA models capture human judgment; World Models capture physical truth. Together, they represent something closer to genuine environmental understanding than either achieves independently.
Speakers identified three specific capabilities that will define whether next-gen autonomous driving AI systems can actually be trusted in real-world deployment.
Thinking — not in a vague sense, but in terms of interpretability. Can engineers understand what’s happening inside the model’s reasoning process? This matters for safety certification, regulatory approval, and, frankly, public trust. A system that can’t explain itself is one that regulators and insurers can’t sign off on.
Control — ensuring that a model’s predictions about the future remain physically consistent with what a vehicle can actually do. Imagining physically impossible futures isn’t creative. It’s a liability.
Long-horizon rollout — arguably the most technically demanding of the three. Decisions made at one moment may not reveal their consequences for several seconds. A lane change that looks reasonable at T=0 might create a genuinely dangerous situation at T=4. Systems that can’t simulate far enough ahead will always be reactive rather than anticipatory — and reactive, in autonomous driving, often means too late.
Broader takeaway from this part of the workshop was pointed and direct: manually coding edge cases is not a viable long-term strategy. Scale — in models, in data, and in learning objectives — is the path forward. That’s not a controversial claim anymore. It’s the working assumption of virtually every serious player in the space.
Ashok Elluswamy’s presentation was the most operationally specific look at how one of the industry’s most closely watched players is putting these ideas into practice.
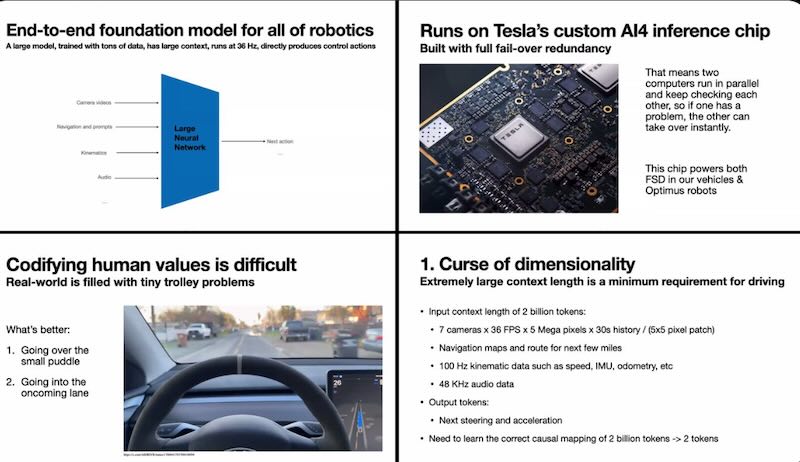
One of the more technically striking disclosures was Tesla’s continued use of fully redundant FSD execution. Two independent processing paths run simultaneously, each continuously validating the other. If that architecture carries into FSD v14.3, it means the production system is effectively operating on half of its available compute — the other half reserved entirely for fault tolerance and redundancy. That’s not inefficiency. That’s the design philosophy of a company that’s serious about operating without a safety driver.
Beyond compute, Ashok noted that Tesla’s redundancy push has extended into power distribution, electrical systems, vehicle communications, and actuation. The company isn’t just writing smarter software. It’s building vehicles architected from the ground up for autonomous operation — which is a meaningfully different thing than bolting autonomy onto a conventional car.

Perhaps the most forward-looking idea to come out of Ashok’s presentation was the first official discussion of Digital Optimus, Tesla’s computer-use agent initiative. Unlike the cloud-dependent agent platforms being developed by companies like OpenAI or Anthropic, Tesla’s approach appears oriented around running these systems natively on its in-vehicle AI4.
Longer-term concept is audacious: using the idle compute of parked Tesla vehicles — distributed across time zones, available around the clock — as a kind of decentralized processing network. Since privately owned cars spend the vast majority of their lives stationary, and since nighttime moves continuously around the globe with time zones, the theoretical availability of that compute pool is surprisingly consistent.
Practical obstacles are real, and Ashok didn’t pretend otherwise. Communication overhead, hardware wear, owner participation, and security all present serious challenges. But it’s the kind of idea that sounds impractical right up until it doesn’t — and Tesla has a track record of making impractical ideas work at scale.
Here’s the number that reframes everything: according to Tesla’s framework, FSD processes the equivalent of roughly two billion units of sensory input at every decision horizon. Seven camera feeds. Navigation data. Vehicle dynamics measurements. Audio signals. An enormous, continuous torrent of environmental information pouring in every fraction of a second.
From all of that, the system produces exactly two outputs.
How much to steer. Whether to accelerate or brake.
That gap — between two billion inputs and two outputs — is where autonomous driving AI actually lives. It’s not purely a perception problem. It’s a causal compression problem: learning which tiny set of actions correctly reflects the physical and social reality embedded in an overwhelming stream of sensory data. Ashok’s argument, implicit throughout, is that intelligence isn’t a feature you add on top of this process. It emerges from this process, given sufficient scale and the right training objectives.
Liu Xianming’s perspective from XPeng echoed a similar conviction — that the industry’s path forward runs through better world modeling and longer rollout horizons, not more handwritten rules.
Whether today’s architectures are already crossing that threshold, or whether we’re still in the early chapters of a much longer story, is a question neither Ashok nor anyone else at the workshop was willing to answer definitively. And that, honestly, is the most honest thing anyone said all week.
What’s clear is this: autonomous driving AI isn’t just watching the road anymore. It’s learning what the road means — and that changes everything about where this technology is headed.
Related Post
Tesla FSD V14.3.3 Update: 8 MPH Summon & Intervention Tracking
Vision-First Autonomy: Horizon HSD Approach to LiDAR and Camera Perception Systems
XPeng VLA 2.0 Drops LiDAR for Vision-Based Self-Driving, 99% Fewer Hard Brakes