
The autonomous driving debate has long centered on a single question: cameras only, or everything plus the kitchen sink? While most legacy automakers and AV startups have doubled down on sensor arrays—stacking LiDAR, radar, cameras, and ultrasonics, Tesla has consistently argued that pure vision is the superior path. Yun-Ta Tsai, senior engineer on Tesla’s AI team has offered one of the most technically rigorous defenses of that position to date, and it reframes the entire conversation around a concept most people outside ML research rarely consider: compression.
Yun-Ta’s argument isn’t rooted in cost or simplicity. It’s rooted in information theory, it’s worth understanding why.

Core insight is deceptively straightforward. In large language models, you can scale context windows to extraordinary lengths and still extract high-quality outputs. Training pipeline handles it. Real-world autonomous driving, however, doesn’t have that luxury.
Longer your temporal data context, the more storage it demands. And critically, the more interesting the data, think a chaotic intersection, an unexpected obstacle, adverse weather, harder it is to compress. Routine highway driving compresses cleanly. Edge cases don’t.
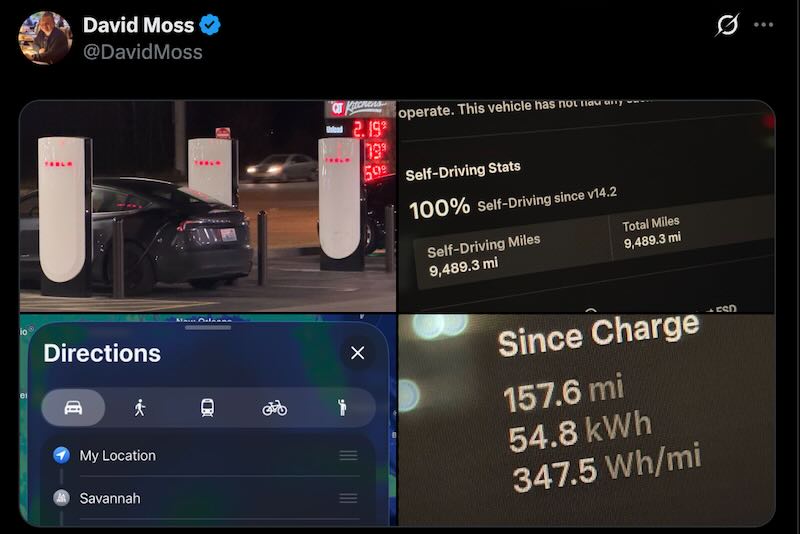
What does that mean practically? No matter how capable your sensor hardware is, your perception system’s effective ceiling is defined by dynamic range after compression, not raw input quality. That’s the constraint engineers are working within, whether they acknowledge it or not.
Here’s where the The Sensor Wars argument gets genuinely counterintuitive. Adding sensing modalities, especially those with fundamentally different statistical distributions, doesn’t expand your information budget. It dilutes it.
Each additional modality competes for space within a fixed compression and quantization budget. More modalities you integrate, the less fidelity each one retains. There’s no free lunch in the information pipeline.
Yun-Ta draws a striking parallel to human biology. Human eyes aren’t designed to see ultraviolet or near-infrared wavelengths by accident or evolutionary oversight, it’s an optimization. Visual system is tuned to maximize compression efficiency across neural pathways while maintaining the signal-to-noise ratio required for long-context reasoning. That’s a deliberate architectural tradeoff, not a limitation.
Insects illustrate the other end of the spectrum. Higher sensory sensitivity, minimal context window, no capacity for complex reasoning. More sensing doesn’t equal more intelligence.
Responding to the post, Elon offered a characteristically terse synthesis: “Intelligence seems to be semantic compression and correlation.”
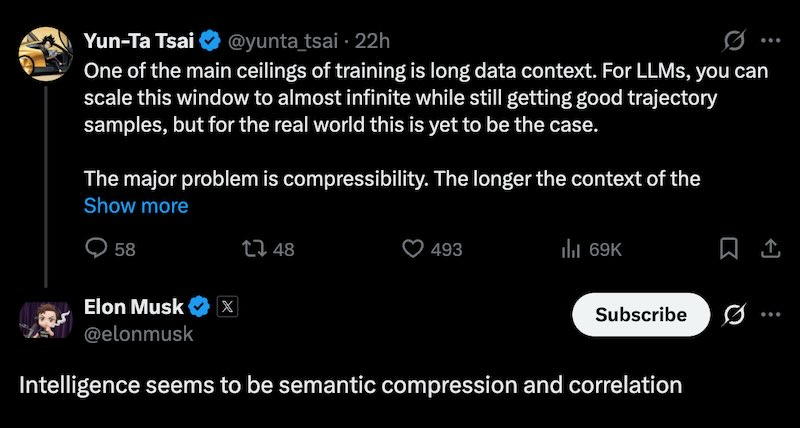
It’s a reductive statement, but it aligns with the underlying argument. What makes an AI system capable isn’t the volume of raw data it ingests—it’s how efficiently it distills long, noisy data streams into structured, meaningful representations. Generative models face the same constraint. Even when forced to run at higher numerical precision, they’re still super-resolving a quantized observation. The compression dynamic doesn’t disappear; it just shifts.
This framing has significant implications for how the industry thinks about autonomy stacks. If semantic compression is the binding constraint, then architectural decisions upstream of the sensor layer—how you represent, encode, and reason over data—matter far more than adding another sensor type to the roof.
Debate over vision-only versus multi-sensor fusion won’t resolve itself in a single post. But the compression argument introduces a rigorous framework that moves the conversation beyond marketing specs and hardware comparisons. In The Sensor Wars, the winner might not be the team with the most sensors, it might be the one that compresses the smartest.
After all, in autonomous driving, it’s not what you sense. It’s what you make sense of.
Related Post
Tesla Drops Lidar/Radar from FSD: Vision-Only Future Ahead for Autonomous Driving
Former Tesla AI Director Andrej Karpathy Calls HW4 Model X “Amazing” – FSD Makes Quantum Leap
Tesla FSD Hits 1.1M Users as Subscription Model Takes Over, 120 EFLOPS of Compute Power